
On the last day of 2024, it is a good time to reflect on the changes. What a year it has been.
Big advancements
It's wild to consider that Claude 3 Opus was only released in March of 2024. It was super expensive, slow, and not decisively better than ChatGPT in any meaningful way, but it was better. Of course, the fast-follow of Sonnet 3.5 was huge for Anthropic - they finally landed something in the sweet spot of quality and cost, with its specialty expertise in code letting it make serious headway. That was Jun 20, 2024.
It was also the Year of the Llama as Meta's Llama 3 launched Apr 18, 2024. It was followed with 3.1, 3.2, and 3.3, and supporting infrastructure of Llama Stack which is probably underappreciated at the moment.
Then there was the endless drama about OpenAI's model code-named Strawberry which turned out to be the o1 family. It's only really just not getting released to the public - OpenAI has a real knack of having things that look amazing and taking a really long time to release them. Some, like o1, turn out to be pretty solid. Others (looking at you, Sora) just end up being disappointing.
Open Models
It was just prior to NeurIPS 2023 in December 2023 when Mistral famously dropped their quiet torrent of the 8x7B model. In many ways, I felt like that was a bellweather moment for open source AI. This was the "as good as 3.5 Turbo at home!" moment.
For context, neither of those models ranks in the top 100 of the LMSys Arena Leaderboard.
Instead, the accidental Llama 2 followed by Mistral's models, Llama 3, and then open source models like Qwen 2.5, Deepseek v2/2.5/3 led us to this auspicious moment.
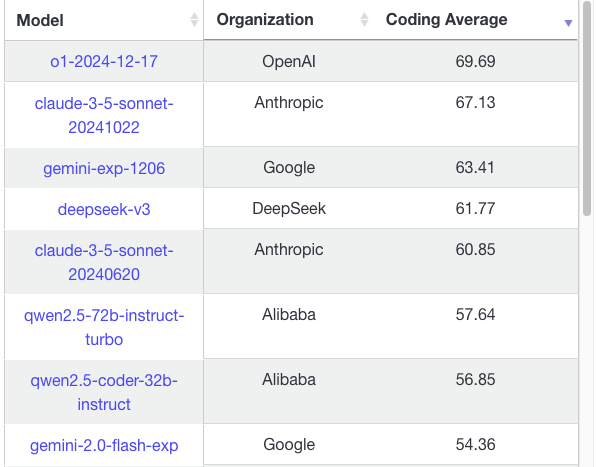
This isn't just theory - if you dug around in the Kamiwaza Slack, you'd find several occasions where our developers would report Qwen2.5-Coder-32B solving something where both Claude 3.5 Sonnet and GPT-4o would fail.
OpenAI and Anthropic retain a lead, and Google may have finally arrived
On the other hand, I'd be remiss if I didn't mention that OpenAI and Anthropic held onto a lead. Anthropic's Claude 3.5 Sonnet is simply amazing at code and in general, for what used to be the most obsequious of models it has a great tone and can be downright funny. OpenAI's GPT-4o remained excellent, but was never as good as Claude 3.5 Sonnet in coding tasks. However, OpenAI released o1, and the o1 models continue to be astoundingly good. They're simply slow. One can see a clear connection though.
Google may have finally awakened the sleeping giant. Gemini 2.0 flash is a beast especially if it remains at "flash" pricing. I'd say that:
- OpenAI's o1 clearly has a reasoning edge especially on high compute, with the unreleased o3 appearing from the teasing to be absurdly strong (and almost unusably expensive)
- Claude 3.5 Sonnet is still the best code model, with o1 pro/full possibly edging it out barely, but in most cases this being an academic victory due to Sonnet being much faster/cheaper
- Gemini models have serious potential - but Flash is oddly strong in some areas, oddly weak in others (coding, for example, where Gemini 2.0 flash underperforms both Qwen 2.5 and DeepSeek v3 along with Sonnet and o1)
Applied GenAI Engineering is still lacking
Earliest adopters: tech startups, large SaaS, cloud providers.
Those were your early GenAI leaders.
Startups like:
- Jasper
- Character AI
- Perplexity
- Midjourney
SaaS companies like:
- Notion
- Adobe
- Salesforce
- ServiceNow
And of course the CSPs.
What was really lacking was big GenAI Enterprise success stories. I chalk this up to a few factors:
- Enterprises value safety over velocity
- SaaS/Cloud/Tech companies are all acclimated in different ways to hyper-velocity, both culturally and structurally
- Enterprises often have under-softwared business processes when you look at their non-SaaS efforts; "the world is run on Excel" isn't too far off (and if you grouped Excel and COBOL together it's probably a lot more!)
- Enterprises are custodians of a lot of PII/PHI and other sensitive data
- There was a fair amount of early handwaving about the Samsung code getting into ChatGPT
Shadow AI: the ghost of Shadow IT / Shadow cloud
Starting in the very late 00s, going into ~2015-2016 (which I think of as the "years of capitulation" to cloud), there was a lot of "shadow IT". Everyone played on this - vendors doing cloud PS etc would harp on this to sell their transformation/migration services; orgs like VMware (where I was employed from '10-'12) would use it as a way to advocate upgrading VMware environments to "private cloud" (the cloudwashing of "private cloud" is the stuff of legend now).
Now we have shadow AI. This is employees who are forbidden from using various tools and services, but who are using it anyhow. The BYOD era and multi-modal models makes this easy. You have so, so many ways:
- Vanilla "just use it"
- BYOD office tethering on cell to hit LLM services
- VPNs
- Take a pic/screenshot/email and other similar versions of "get around the firewall"
That last one is in some ways the most hilarious and bad - some employees are redistributing sensitive data 2-3x just to get around restrictions meant to avoid it.
By the way, a hard bad on all AI is very likely to keep this up no matter how hard you try to advocate to stop it. Counter it with:
- Make good tools available - at the very least, an internal stack - Kamiwaza can help here with the ability to easily operationalize your own models and services, and our out-of-the-box tools include things like a chatbot.

- Select providers that have compatible privacy/security policies and educate your employees on settings - good example being that OpenAI lets anyone opt out of sharing data to improve the model, but for personal accounts this has to be turned on by the user.
- Educate and don't just dictate. Help the employees understand the "why" of the policies - being transparent about your regulatory and contractual obligations can help them understand the burden and adhere.
The real value in Enterprise AI
The real value in Enterprise AI use is not anything fancy. It's actually not anything groundbreaking at all except in efficiency. It's the boring stuff - repetitive, low-value but utterly necessary tasks - where AI excels. Consider how many people have a signifiant part of their job being the non-challenging knowledge work:
- Parsing documents
- Making computations
- Entering values into systems
- Getting values out of systems
- Running (or writing but less so) reports
These activities are often linked to huge stables of "line of business" applications - software where it is too specific to the enterprise to be pulled into a platform like Salesforce or ServiceNow, but which is nonetheless necessary. These are ripe for AI - not just to agentically handle the tasks, but to upgrade/improve that software.
This is so remarkably strong that one bright spot is the assault on vertical SaaS. There's a great a16z blog on it. As Joe Schmidt wrote, the startups are "drinking the milkshakes" - a reference to the amazing There Will Be Blood meme:

An incredible movie and an incredible strategy.
Rethink everything you know about the nature of software, because as the cost of LLM tokens goes down and model intelligence goes up, the cost of software is on its way to zero.
This is so unbelievably profound. As a developer you can opt to be terrified by this (very reasonable) or utterly thrilled. I cannot predict what happens here. We are seeing the unmovable object meet the unstoppable force here -- on one hand, ~free tokens means AI-powered software engineering is going to replace and automate an unbeleivable amount of work. Some will be done automatically. Some will be done assisted. Some little left will be done entirely by human ingenuity.
But that's only one force. The world is filled with bad or missing software.
What happens when you can spend an afternoon with a tool and have a full clone of Nextdoor+Facebook for your neighborhood?
No one knows this answer, but this is a thing underlying Jevon's Paradox. As the cost of some things goes down, demand goes up. And there is a very clear picture that demand is much, much higher for software if the software is ultra-cheap.
It also disaggregations the entire "software-industrial complex". I mean the chain of designers, frontend devs, backend devs, agile, scrummasters, project and program management, software engineering managers - it's unbelievably complex and cumbersome. The fungibility of AI is so wild. At kamiwaza we're bringing an app garden out. It's a great fit, as tons of apps work really well, especially privately, if you just give them a decent model and make deployment easy.
So rather than trying to break out Balsamiq like I would 10 years ago, "Build me a page that..."
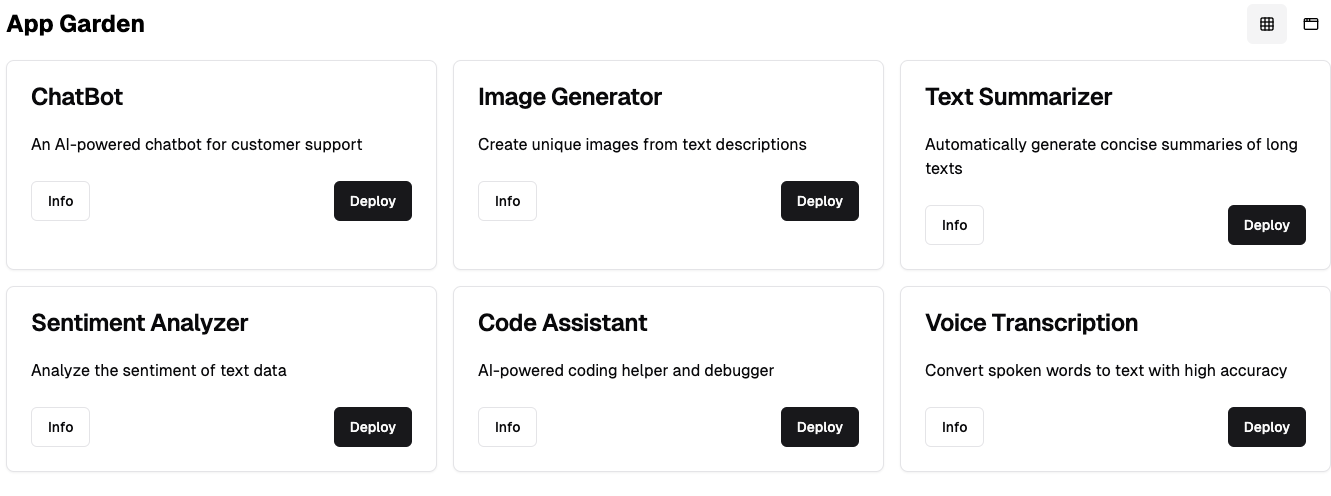
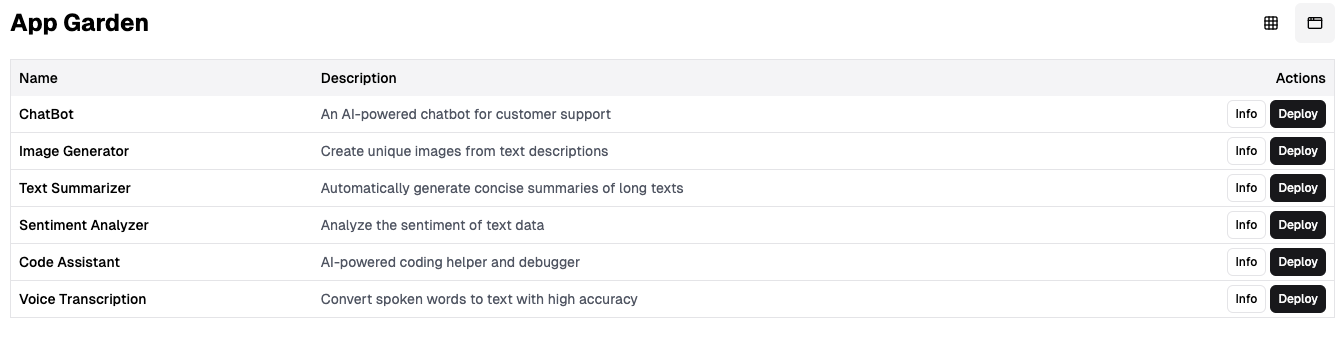
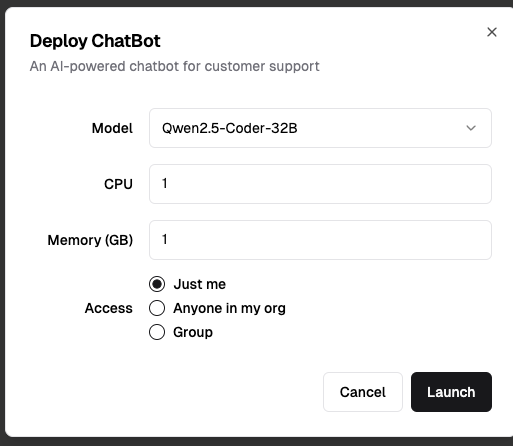
(As I typed this, AI even autocompleted most of the bottom 2 images)
This era of "do more better cheaper faster" is here now, it's just not evenly distributed yet.
The Dawn of AGI
I wrote a lengthly post on OpenAI o3 conquering the ARC-AGI bnechmark. People have differing opinions on how legitimate this is, or how significant. I'm by no means the final authority on such a thing; but as I outline, I do believe that François Chollet has been a consistent skeptic of "thinking" by LLMs, and when he says
It scores 75.7% on the semi-private eval in low-compute mode (for $20 per task in compute ) and 87.5% in high-compute mode (thousands of $ per task). It's very expensive, but it's not just brute -- these capabilities are new territory and they demand serious scientific attention."
This is an extremely notable departure from that skepticism. He's not calling it AGI. That definition is much-debated and stories like OpenAI and Microsoft saying $100B in profit is what defines it isn't helping.
That said, having started to get a good amount of stick time with o1-pro, I will say its answers are materially stronger than average. It sheds the gpt-4o tendency to make "easy" mistakes or, worse "forget" input context. (For what it's worth, Claude was an early "look at our huge context" leader but that context was absolute trash.)
It's an interesting contrast because a lot of people listened to Ilya Sutskever's NeurIPS talk and thought he said "pretraining is over" - which he did in a sense, "we have but one Internet" and called it "the fossil fuel of AI".
But those people leave out his next slide:

These are all interesting. I am not a researcher so as an expert at reading the tea leaves I could prognosticate but that's a story for another post.
Suffice it to say, the story of LLMs in the past 2 years is:
- Clean data is better
- More clean data is better
- LLMs get better results when trained to approach the data in different ways (papers on training LLMs to do math well are illustrative here if you care enough to dig into this!)
But beyond that:
Agentic workloads will drive feedback mechanisms
If you are an advanced Claude user, you're probably using Model Context Protocol plug-ins. (You should.) But you may also have noticed how Claude 3.5 Sonnet is really smart about how to use them, about how OS-level things work - it's just "clean". I have exactly zero insider knowledge here, but I can practically guarantee you there is a substantial farm of Claude bots with a ton of purview to run around and build and evaluate stuff which slowly digest their energy back into really clean training data. I'd love to know if any of it ends up in a pre-training zone, or if this is all used in fine-tuning/DPO/RLHF/etc efforts; but regardless.
Which are a form of synthetic data
Getting a model to interact with anything which can provide full win/lose level reward function judgments is a form of synthetic data. This is one reason why code models are just so tempting: almost all code can be evaluated in a deterministic way, and often in a functional way as well. This provides the feedback mechanism to generate synthetic data to improve training. This is undoubtedly a major hope for OpenAI - that o1/o3 doing inference-time compute can generate mountains of synthetic data to improve training on non-thinking models. Pick any class of question ("How many R's are in strawberry?") and if o1/o3 can get through it the vast majority of the time but the core model fails, that's likely an improvement that makes it into said model.
We are distilling human knowledge
This is what distillation of knowledge is. I don't mean distillation at the model level, which is about using the guidance of a bigger model to get it's intelligence into a smaller model - whether that's via tuning, training, or direct manipulation of the model's weights.
No, I mean "we are separating the wheat from the chaff". We are taking high quality data and using industrialized thinking to analyze it to continue to condense it to be the best version of itself. LLMs may remain stochastic, but a random selection between 10 excellent options is better than 1 excellent, 4 good, and 5 average-to-mediocre response options. This runtime-inference to synthetic training data pipeline is in its earliest days, so there's little to evaluate the efficacy other than the enormous success of high quality data in improving model performance in general.
The entire idea of model collapse as one of those "much ado about nothing" things. (It's ironic that the Nature publication was ~6 months after the pre-pub, by which time this had gone from "hey this is concerning" to "ok, actually, synethic model-generated data can be AWESOME for model quality when done right")
The Era of Tools is Upon Us
If you haven't yet been using Claude with MCP tools, you need to run-not-walk and give it a whirl.
It's simply a nice workflow. It's early days, but I feel relatively safe predicting:
- There will be a proliferation of tools built around MCP, because developers have to write them and devs love Claude
- The architecture of the tools with both open clients and open servers strongly supports a network effect
Which means I think we are seeing a de facto standard for tools emerge.
OpenAI may well be the last that wants to adopt this. Which makes sense, they had function calling so long ago - but to be fair, MCP looks like a master stroke compared to their implementation. Partially because of how open it is. Partially because of all the code. But most importantly:
It is baked into Claude the client in a very clean, super usable way and so adoption is going to be enormous.
It's interesting that OpenAI made it so hard to leverage tools with GPT, which makes the Claude MCP version look like a master stroke. It's all local, it's all open. So something like the above where Claude is just editing code is super easy and takes less than 5 minutes to get going locally and the value is utterly off the chart. In many ways I find using ChatGPT a bit painful by comparison, not because of model quality, but because the tooling is just so much better.
Another example of tooling for the win here is the overwhelming popularity and love of Claude Artifacts. The artifact as an encapsulation of a piece of code or such is great, and the idea that Claude could render it to show you something like a preview of react is great too -- but the real win is the integration with projects. Getting the AI to take notes and adding it to the project is huge. It's very limited in a sense: all that data is just in the context for every request, which makes it eat a lot of token capacity, with the attendant implications for conversation length and number of messages you can effectively use. But it's so useful and Claude really does appear to treat all that material like it is just "in the conversation.
This is a remarkably different experience from a custom GPT on ChatGPT and giving it documents, where it clearly does some sort of RAG. Upside there is you can feed it a lot more data, but the downside is: the model is VERY likely to not notice it.
Even in cases where you literally paste a lot of context into the chat window, GPT has a tendency to say something like:
Your file.py should probably look something like:
if __name__ == "__main__":
print("Hello, world!")
To which you want to reply: Why are you saying "should look something like", I literally pasted that file in with a '# /path/to/main.py'!!!!
What I'm expecting to see is more open models trained EXPLICITLY on MCP. This will drive more adoption of MCP for tools, which will drive more model training.
When ChatGPT gets MCP, explicitly or implicitly, that may feel like the final nail in the coffin. But Anthropic had massive pole position on this.
Hardware Remains an Unbelievable Blocker
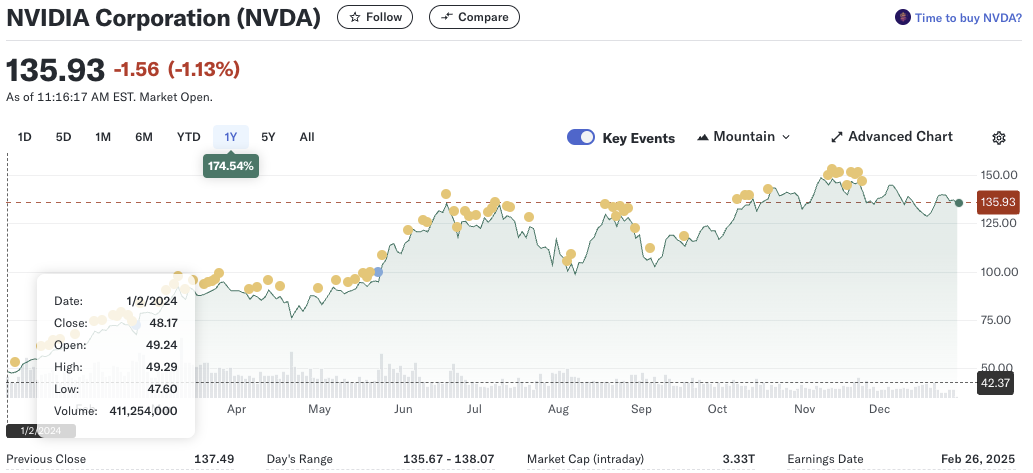
It's been a great year for nVidia. Adding $2T of EV is the stuff of legend, but nVidia continues to enjoy a pretty amazing lead in both market share, mind share, and software sophistication that makes it the envy of the industry. It now has a lot of competition aiming to take some of its share (or, drink its milkshake, as it were).
Despite that, they mentioned Blackwell being sold out a year in advance.
This is not any sort of surprise to me. There are all manner of GPU supply constraints. As I went to get custody of an 8xH100 SXM cluster, I was waiting in line. Azure is topping out at 2xH100 instances, you still can't even get an 8xA100 for a large model, etc. Constraints abound.
There was more drama behind Altman's supposed "Fundraising for $7T" which turned out to be him advocating for a much larger investment in chip design and fabrication. This makes sense, as nVidia's margin is, to some extent, OpenAI's opportunity and vice versa. (nVidia clearly owes a debt of gratitude to OpenAI for the AI boom, but that can only go so far. What have you done for me lately?)
More of the unstoppable force / immovable object analogy here:
- nVidia is crushing it
- Blackwell is sold out
- Enterprise inference is <1% of its final form
- Even while models are driving $/token costs through the ground
Maybe some "real" analysis can shake this out - but there's clearly a tension here. And yet you can see that if o1/o3 are similar for quality models in the short term, we indeed must be lacking horsepower.
Clearly, models thinking through complex problems is useful but also inferentially costly.
And yet it's no surprise this works - eliciting chain of thought had a tendency to work better merely because of the autoregressive nature of the models - "changing your mind" isn't something a model does without tokens. And "just give your answer and no explanation" was actually a great way to tank results.
In Conclusion
2024 was a heck of a year. Outside of what's going on in the space, of course kamiwaza went from a dream to a product to a company, and now a well-funded one at that. Speaking of which, we're hiring!
Check out some details on our open roles!
Happy New Year!